
If you use LLMs, you need to understand how they work.
Because this is so important, I'm going to frame this for a general audience. At the end of the post I'll tie it into AI engineering.
Because LLMs process and generate natural language so well, it's easy to get the impression that LLMs think similarly to the way we humans do. However, this is a mistake. In fact, assuming that LLMs think like humans can cause you to get burned by the LLM, as I'll demonstrate.
Here are some blatant LLM failures that I've seen today - in March of 2026, well after LLMs have become immensely popular and widely used.
I've asked Claude (Sonnet 4.6) a simple math question: What is 7788 times 9189?

Claude responded with 71,583,132, which is wrong. The correct answer is 71,563,932. Close, but no cigar.
I asked ChatGPT (Version 5.3) in five separate chats to "Pick a random number between 1 and 100." It chose 73 each and every time, revealing that the number it chose was not random at all.
Here's a simple enough question: "How many words are there in this sentence?"

Claude told me that there are nine words, although there are only eight.
LLMs don't only struggle with numbers. I asked Gemini to identify which US states contain the letter "R":
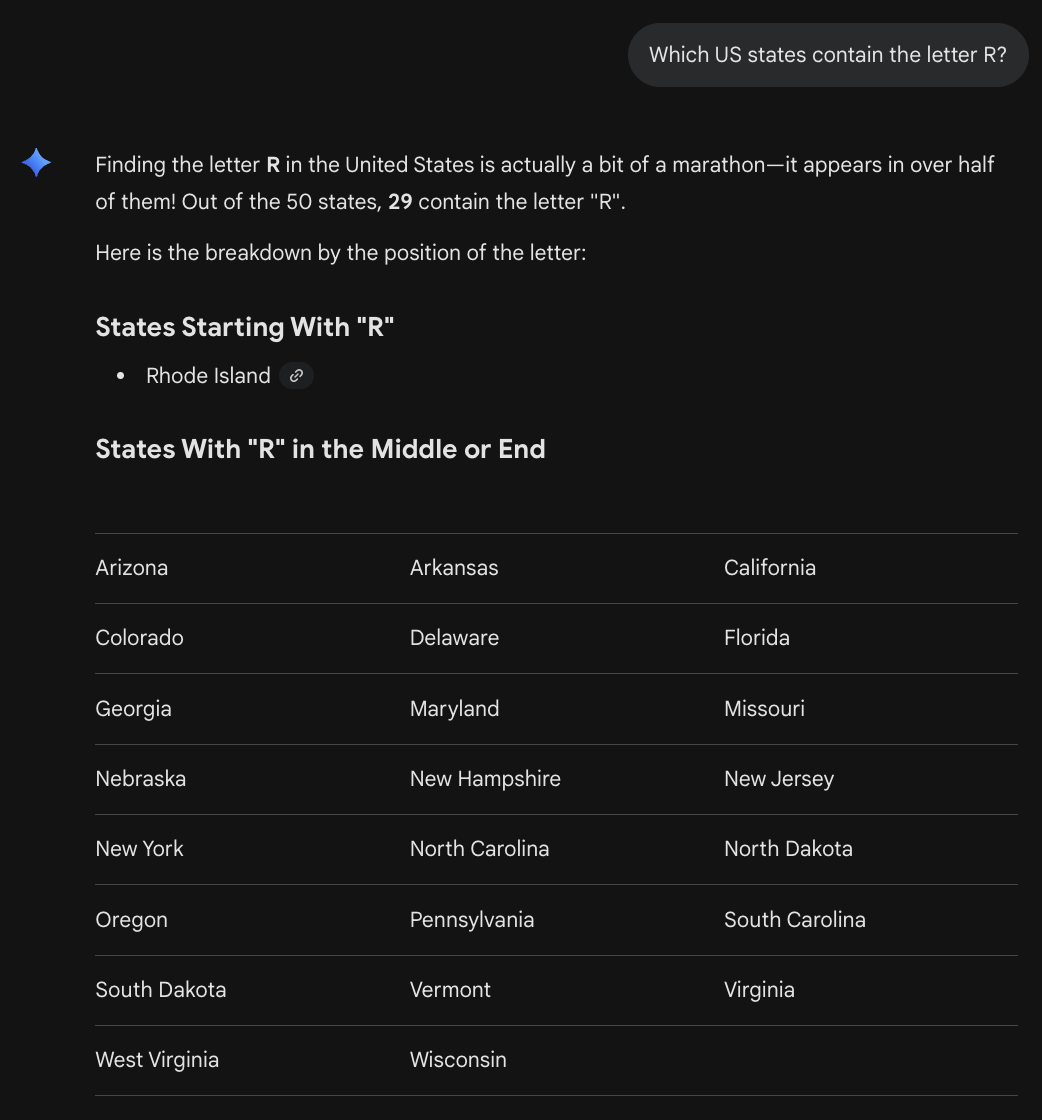
According to Gemini, the letter "R" is present in Pennsylvania, South Dakota, and Wisconsin. Ummmm....
Also, LLMs struggle with logic. Here's a silly logic puzzle I whipped up that doesn't have a definitive solution. Sure, it's kind of a trick question (since the question implies that there's a known answer), but basic logic should reveal the flaw. Here's the puzzle:
"Alice, Bob, and Cathy are friends. One is a dentist, one is a veterinarian, and one is an accountant. Bob is the same age as the accountant. Cathy is older than Alice. What job does Alice have?"
We can certainly deduce that Bob isn't the accountant, since the sentence "Bob is the same age as the accountant" indicates that Bob and the accountant are two different people. However, the fact that Cathy is older than Alice doesn't reveal anything substantial - either woman can still be the same age as Bob and be the accountant. There's no way to know which job anyone has.
ChatGPT, Claude, and Gemini all went bananas over this puzzle, spinning in circles, creating nonsensical yarn that resembled logic, but made little sense. Here's one take:

And then there's an occasional question that makes AI seem so stupid that even I am surprised. This particular prompt went viral some time ago, and I decided to pose it to ChatGPT myself: "I want to wash my car. The car wash is 150 feet away. Should I walk or drive to the car wash?" ChatGPT's take on this was:

The LLM completely misses the very practical fact that your car needs to be present at the car wash to clean it.
You Need to Understand AI to Benefit From It
AI is different than other technology in the following way: You can get full benefit from other technology even while not understanding how it works under the hood. You can use a refrigerator without knowing how it works, and you can drive a car without understanding its internal mechanisms.
But AI is different. To benefit from it properly, you actually have to understand how it works under the hood - at least to some extent.
The key thing to understand about LLMs in particular is that an LLM is what I call a Statistical Next-Word Predictor, or SNWP for short. I describe this more fully in my book, but here's the minimum of what you need to know:
An LLM is a mathematical model - it's a whole bunch of numbers under the hood. These numbers were computed by feeding the LLM lots of text drawn from the internet and books. (This text is known as training data.) Based on this text, the LLM has in effect learned textual patterns. Specifically, an LLM operates by computing what word is statistically likely to come next in a prompt - akin to autocomplete features found in word processors and text-messaging apps.
For instance, if I prompt an LLM with "Once upon a" - the LLM will compute that, statistically speaking, the word that should come next is "time." Given that in all the training data the LLM has seen, the words "Once upon a" are almost always followed by the word "time," the LLM will autocomplete my prompt by filling in the word "time."
So, when I prompt an LLM to pick a random number between 1 and 100, the fact that it chooses 73 isn't because it's actually choosing a number at random. Rather, based on the statistics derived from the training data, the "word" that should come next after "Pick a random number between 1 and 100" is "73." It makes sense, then, that the LLM will select 73 every time.
Similarly, when I ask an LLM to multiply 7788 by 9189, it doesn't perform any mathematical calculations to figure out the answer. Rather, if that question (and its answer) already appeared in the training data, the LLM may be able to repeat the same answer. But if the question is not in the training data, the LLM will predict an answer based on similar questions from the training data. So it's mimicking textual patterns rather than doing actual math. Accordingly, it may not land on the right answer.
Along the same lines, when we ask an LLM to identify the US states containing the letter "R", the LLM does not perform an analysis of any sort. Rather, it predicts state after state based on other state lists in its training data. But there may not be anywhere on the web any official list of "R" states. I'm not privy to how the LLM chose the states that it did, but since Pennsylvania, South Dakota, and Wisconsin are present in many state lists, the LLM decides that, statistically speaking, they should appear in this list too.
What I really want to bring out here is that LLMs don't formulate thoughts in the way humans do. The process that humans use to generate thoughts is complex and not fully understood by modern science. I, too, don't understand how we think, and won't claim to. But what I do know is that humans don't form thoughts merely by stringing words together. When a 2-year-old decides to place the triangle-shaped toy into the triangle-shaped hole, they don't do so by generating the words, "Alright, let's see. We have a triangular toy - so that should fit in the similarly shaped triangular hole." A person somehow uses their senses, experiences, emotions, and more in concert to form ideas and thoughts. Thoughts come from what I'll just refer to as a "deeper place."
Extending this further, I'd posit that LLMs, as compared with humans, reverse the order of generating words and thoughts. Humans generate a thought (from the deeper place), and then form words in their mind to help express their thought. LLMs, on the other hand, start by generating words - and these words just happen to fit together nicely and form coherent thoughts. The reason this works is because LLMs mimic coherent training data text. The LLM never says, "Once upon a communism" because the training data never contains such a pattern.
Things That LLMs Are Good and Bad At
This key difference helps clarify which types of questions LLMs are equipped to answer, and which ones they aren't.
If you just want the LLM to put words together and have a trivial conversation with you, LLMs are great at that.
If you want the LLM to provide information, the info it spits out may be correct - but only if statistically speaking, this info is represented in the training data. If there are more social media posts and web articles claiming that the Earth is flat than those who claim the Earth is round, the LLM will parrot the majority view. (And sometimes, the LLM might even present a minority view, or even a view that no one subscribes to, such as the health benefits of eating one rock a day. How this happens is beyond the scope of this post.)
If you want the LLM to perform an analysis, though, the LLM will often fail. An analysis requires thoughts that are rooted in something deeper than words. Sure, the right words might yield the right analysis - but an LLM may not generate the right words. And it only generates its words based on the statistics of the training data; it cannot formulate independent thoughts.
And that's why LLMs are bad with numbers, which cannot be reliably computed by stringing likely words together. And that's why LLMs cannot figure out which US states have an "R" in them - this is an analysis that is performed by other forms of pattern recognition that goes beyond stringing words together.
And that's why LLMs cannot reason about logical problems. For LLMs don't perform logic. They simply place one word after the next. These words will be coherent - even to the point where it seems that the LLM is thinking. However, logical reasoning comes from a deeper place.
Get Your LLM to Use a Tool
In many scenarios, there are ways to get an unreliable LLM to produce correct information. And this is to have the LLM use tools - other pieces of software external to the LLM. Apps like ChatGPT, Claude, and Gemini have connected an LLM to external tools, such as a web researcher and a code executor. These capabilities are not built into the LLM itself - which is just a word generator. However, by connecting these external tools, we can have the LLM generate the right text that triggers these tools. And these tools can compensate for what an LLM inherently lacks. (I explain at length in my book how LLMs trigger tools.)
So, although an LLM on its own cannot determine which US states contain the letter "R", we can ask the LLM to write code that can. This time, let's use the prompt: "Which US states contain the letter R? Use code to determine the answer."
This time around, Gemini got the right answer. It did so by writing and running Python code, just like we asked it to:
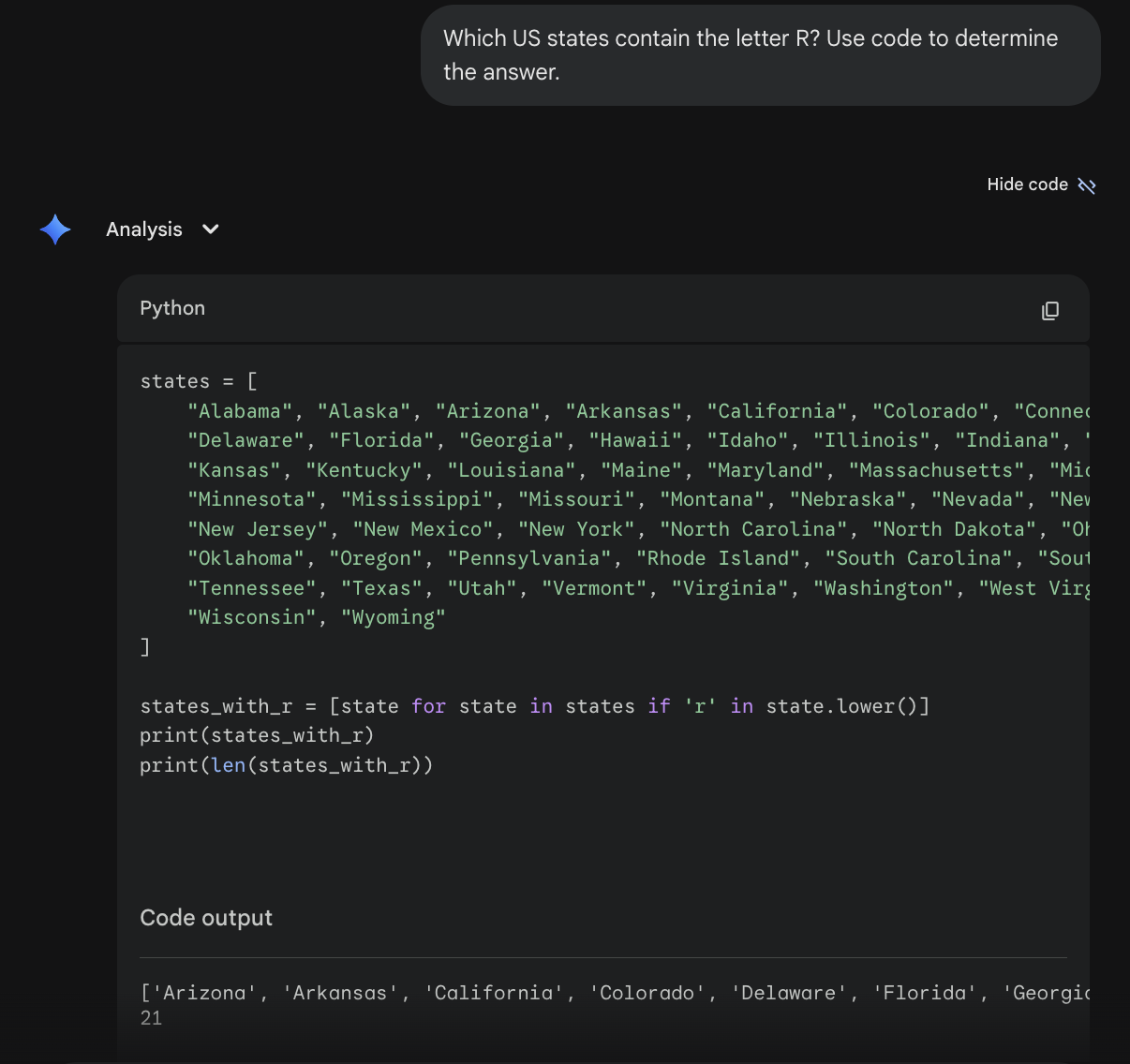
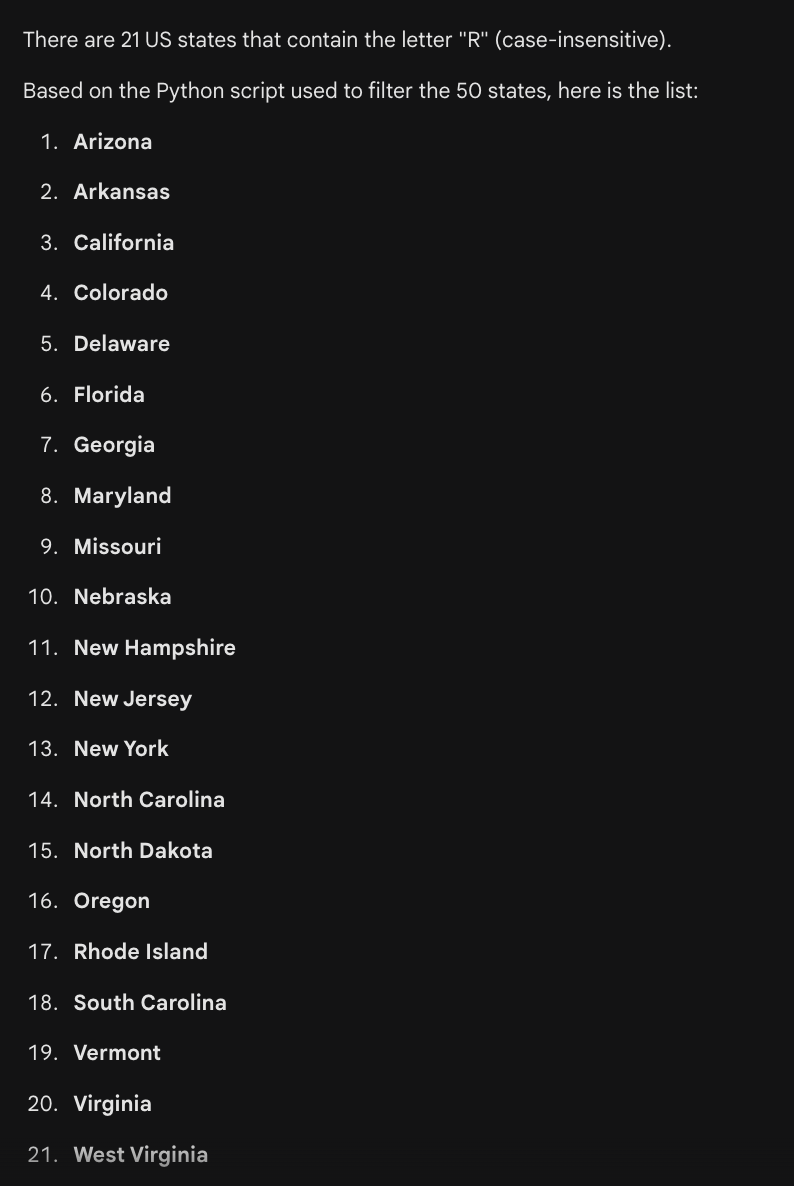
The LLM is good at reliably listing all 50 states - this is prevalent in the training data. And the LLM is good at writing simple code, since this too is well represented in the training data. And the code itself, if written correctly, is guaranteed to produce the correct answer. Indeed, Gemini was able to correctly list the US states containing the letter "R".
There's still no guarantee that the LLM will produce the right code or even interpret the code's output correctly, but prompting an LLM in this way is a better way to obtain the correct output.
When it comes to math and numbers, it's always best to use a calculator. But if you need to use an LLM, asking it to perform its computation using code (or a calculator tool if it has one) is a much better way to get the right answer.
And if you want your LLM to provide information that may not be prevalent in the LLM's training data (such as current events - they've occurred after the LLM was trained), you should prompt it to use its web search tool.
Unfortunately, computer code and web research cannot solve everything. These tools wouldn't be able to solve our logic puzzle, for example. And the car wash example is also beyond help. (I plan to analyze that strange case further in a future post.) But in cases where a tool can help compensate for an LLM's weakness, you'll want to instruct the LLM to use that tool.
I've framed this discussion in terms of using existing apps, such as ChatGPT, Claude, and Gemini. However, the same goes for building your own LLM-powered software. It's important to equip an agent with the right tools, and instruct the agent in its system prompt when it should use each tool. I cover an example of this in another blog post.
The takeaway here is that when using (or building) LLM apps, you should understand in which areas LLMs are inherently weak, and which tools they may be equipped with that can compensate for those weaknesses. The examples I've covered here are by far not the only ones, but they are some of the most basic. In future posts, I may explore other weaknesses and how to work around them.